Martin,
Can you provide more info on WHEA and what it means exactly?
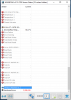
I have a system [ ECS LIVA One : http://www.ecs.com.tw/ECSWebSite/Product/Product_LIVA_SPEC.aspx?DetailID=1645&LanID=0 : running Windows 10 Pro latest RTM build ] that I am monitoring via HWiNFO (latest beta), and I see that the WHEA count is keeping on increasing every second.
The system is quite stable in all our benchmark tests, but I am a bit worried about this WHEA count.
[attachment=1766]
Thanks!
Ganesh
Can you provide more info on WHEA and what it means exactly?
I have a system [ ECS LIVA One : http://www.ecs.com.tw/ECSWebSite/Product/Product_LIVA_SPEC.aspx?DetailID=1645&LanID=0 : running Windows 10 Pro latest RTM build ] that I am monitoring via HWiNFO (latest beta), and I see that the WHEA count is keeping on increasing every second.
The system is quite stable in all our benchmark tests, but I am a bit worried about this WHEA count.
[attachment=1766]
Thanks!
Ganesh
")
